GLM-Image: Auto-regressive for
Dense-knowledge and High-fidelity
Image Generation

Figure1: GLM-Image General Showcase

Figure2: GLM-Image Dense-Knowledge Showcase
Today we are excited to introduce GLM-Image, the first open-source, industrial-grade discrete auto-regressive image generation model. GLM-Image adopts a hybrid architecture combining an auto-regressive module with a diffusion decoder. The auto-regressive part is partially based on, and initialized from, [GLM-4-9B-0414][1] with 9 billion parameters, while the diffusion decoder follows [CogView4][2] to adopt a single-stream DiT structure with 7 billion parameters. In general image generation quality, GLM-Image aligns with mainstream latent diffusion approaches, but it shows significant advantages in text-rendering and knowledge-intensive generation scenarios. It performs especially well in tasks requiring precise semantic understanding and complex information expression, while maintaining strong capabilities in high-fidelity and fine-grained detail generation. In addition to text-to-image generation, GLM-Image also supports a rich set of image-to-image tasks including image editing, style transfer, identity-preserving generation, and multi-subject consistency.
Background: In recent years, diffusion models have become the mainstream in image generation for their training stability and strong generalization capabilities. Yet even with substantial improvements in diffusion modeling and VAE formulation[3][4][5], etc., end-to-end diffusion models still have shortcomings in complex instruction following and knowledge-intensive scenarios, often falling short in both information expression and semantic alignment. At the same time, some newly released high-quality image generation models have demonstrated outstanding performance in such knowledge-dense cases, producing visually rich detail while exhibiting auto-regressive modeling characteristics. Drawing inspiration from these developments, GLM-Image was designed from the beginning with two decoupled objectives: robust understanding of complex information and the ability to produce high-quality image details. In our approach, the auto-regressive generator produces tokens with low-frequency semantic signals, while the diffusion decoder refines high-frequency details to deliver the final image. This hybrid architecture not only performs reliably in general image generation tasks, but also presents noticeable advantages in creative work that demands intricate knowledge representation, pushing image generation toward a new stage that combines artistic aesthetics with precision in conveying information.
Techniques
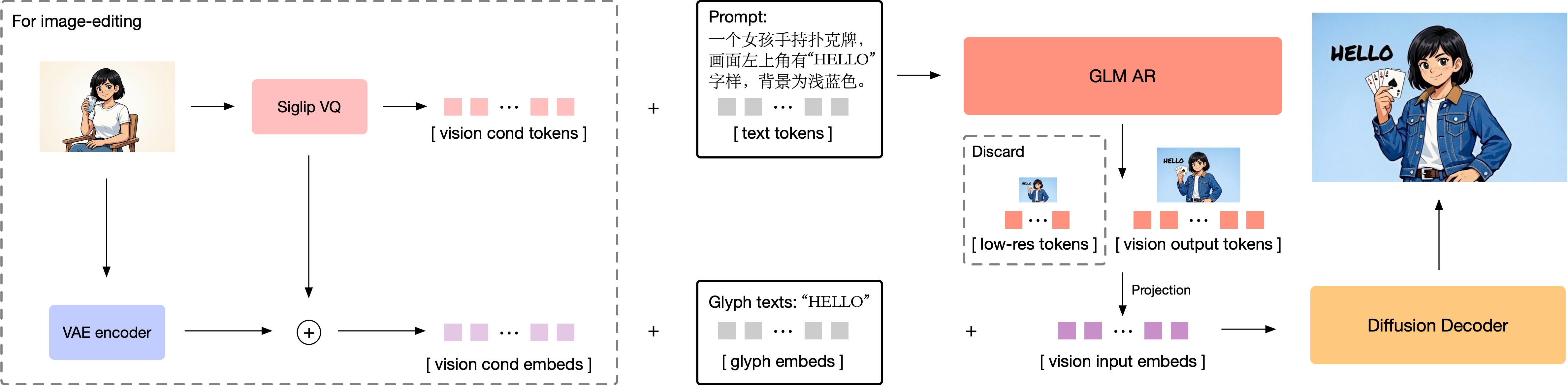
Figure3: General Pipeline
Visual Token Selection
In previous visual auto-regressive generation models, the token types used have typically fallen into three categories:
- Visual codes obtained via discrete reconstruction training (VQVAE[6])
- Visual codes obtained via discrete semantic training (semantic-VQ[7])
- Statistical semantic features extracted from 1D vectors (as in DALLE2[8])
These approaches rank from high to low in the order above from an information completeness standpoint, whereas their semantic relevance tends to increase in the reverse order. For visual generation models, the correlation between tokens (or patches) is a crucial factor influencing both model convergence and the final output quality. In latent diffusion models, works as VAVAE[5] and SSVAE[9] have demonstrated the significance. While for auto-regressive generation, training loss comparison shows a clear different magnitude (~7 vs. ~3) for tokens derived from VQVAE and semantic-VQ with similar codebook size, suggesting that modeling with semantic tokens offers superior convergence properties for visual generation training. On the other hand, 1D vectors suffer from insufficient information completeness and correspondence towards a specific image, and are more commonly used in subsequent works for tasks as subject consistency generation (e.g., FLUX.1 Redux[10]).
Building on these conclusions and observations, GLM-Image adopts semantic-VQ as its primary tokenization strategy. To be specific, we implemented the tokenizer scheme from XOmni for better semantic correlation during token modeling, combined with a diffusion decoder subsequently decoding from these tokens to produce the final image outputs.
Auto-regressive Pre-training
The auto-regressive part of GLM-Image initializes from GLM-4-9B-0414 and implements combinitorial training of text-to-image generation and image-to-image generation. We freeze the text word embedding layer of the model while enabling other parts for training, appending an extra vision word embedding layer for vision token projection and replacing the original LM head with a vision LM head for the new task. We implement MRoPE as the positional embedding for the circumstance of interleaving images and texts from both generation tasks of text-to-image and image-to-image, as illustrated in the picture.
We train the model with multiple resolution stages including 256px, 512px and a mixed-resolution training stage spanning from 512px to 1024px. The tokenizer from XOmni patchifies the image with a 16× compression ratio, which means the token count per sample is 256, 1024 and 1024-to-4096, respectively for the three training stages. Given that we set the upscaling factor of our diffusion decoder’s final output to 32, the resulting image resolution ranges from 1024 px to 2048 px.
In the initial 256-token stage of training, we implemented a straightforward raster scan order for token generation strategy. However, as we advanced to higher-resolution training stages, we observed a drop in controllability of model outputs when applying the same generation approach. To address this, we adopted a progressive generation strategy[11]: before generating high-resolution image tokens, we first generate approximately 256 tokens with the same aspect ratio, obtained by tokenizing a down-sampled version of the target image. Considering that these preliminary tokens largely determine the final image layout, but due to their small number they might receive insufficient attention, we increased their training weight in subsequent stages, which effectively improved the overall generation quality.
Decoder Formulation
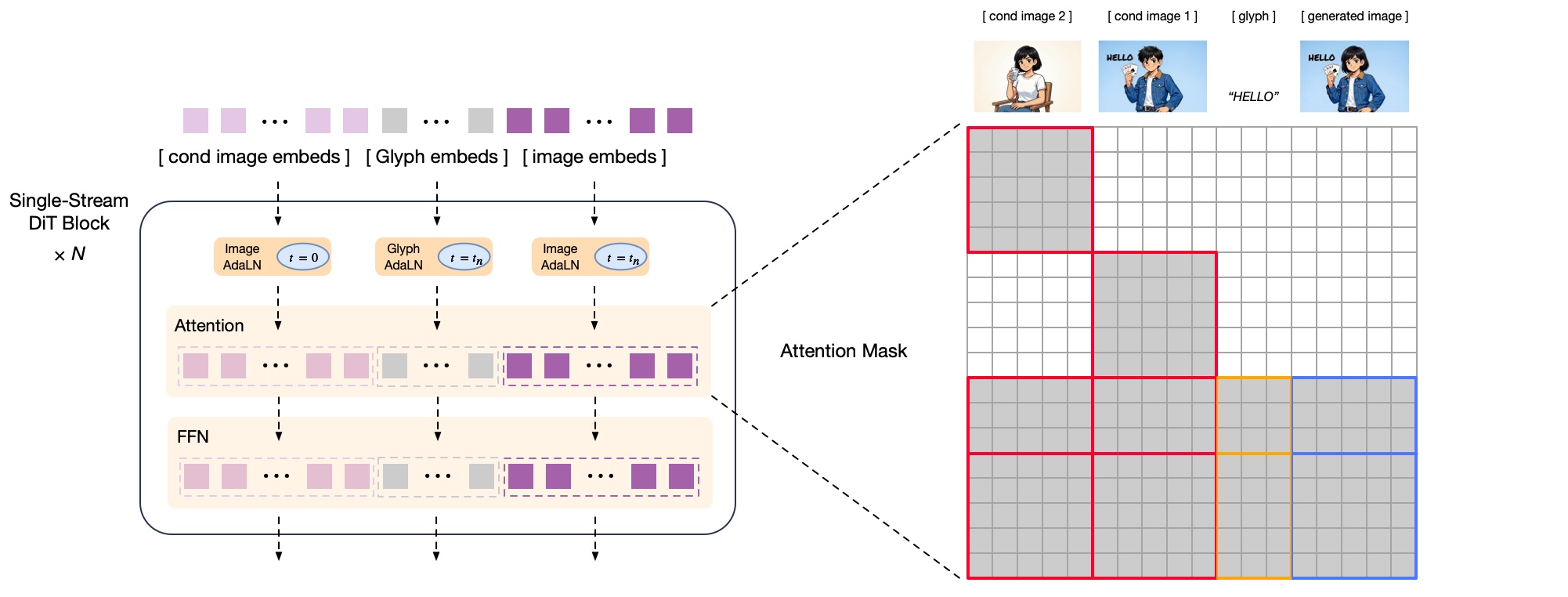
Figure4: Decoder Formulation
The diffusion decoder receives semantic-VQ tokens generated by the auto-regressive model as conditional inputs to reconstruct the target image. While semantic-VQ tokens carry rich semantic information, they discard high-frequency image details and primarily present relatively low-frequency image layout information. As a result, the diffusion decoder must retain a certain generative capacity to synthesize and recover the missing fine-grained details.
For the backbone design, we follow CogView4 to adopt a single-stream DiT architecture. The decoder employs flow matching as its diffusion scheduling strategy, ensuring stable training and efficient convergence for high-fidelity image generation. For integration, the semantic-VQ tokens are first passed through a projection layer and then concatenated with the VAE latent representation along the channel dimension. This preserves the input sequence length and incurs almost no extra computational overhead. Since the semantic-VQ tokens already provide sufficient semantic information, we remove the prompt input from the decoder’s conditioning. This design eliminates the need for a large-parameter text encoder, thereby reducing both memory usage and computational cost. To strengthen the decoder’s ability to render complex textual content—particularly Chinese characters—we introduce a lightweight Glyph-byT5[12] model that performs character-level encoding for rendered text regions. The resulting glyph embeddings are concatenated with the vision embeddings along the sequence dimension.
For image editing tasks, it is often critical to preserve the high-frequency details present in the reference images. The semantic information provided solely by semantic-VQ tokens is insufficient for modeling fine-grained detail preservation. Therefore, in GLM-Image we use both the semantic-VQ tokens and the VAE latents of the reference images as additional conditioning inputs for the diffusion decoder, as illustrated in Figure4. Unlike concurrent image editing models such as Qwen-Image-Edit[13], which apply full attention between reference images and the generated image, we adopt a block-causal attention mechanism between the reference and the generated image. This follows the attention design pattern used in ControlNet-Reference-Only[14]. The block causal attention can significantly reduce the computation overhead on the reference image tokens by kvcache while keeping competitive detailed preservation.
disentangled Reward for AR+Diffusion Post-training
In the post-training stage, GLM-Image employs a decoupled reinforcement learning strategy to separately optimize its auto-regressive generator and diffusion decoder, enabling improvements to both semantic alignment and visual detail quality. Both modules are trained with GRPO[15] optimization. For the diffusion decoder specifically, GLM-Image adopts flow-GRPO[16], a variant of the standard LLM GRPO adapted for diffusion models.
The auto-regressive module focuses on low-frequency rewards that guide semantic consistency and aesthetics, thereby improving instruction following and artistic expressiveness. It combines multiple reward sources, including HPSv3[17] for aesthetic scoring, OCR for enhancing text rendering accuracy and VLM for overall semantic correctness of generated content. The decoder module targets high-frequency rewards to refine fine-detail fidelity and text precision. It leverages LPIPS[18] to improve perceptual texture and detail similarity, integrates OCR signals to further boost text accuracy, and employs a dedicated hand-scoring model to enhance the correctness of generated hands.
Eval metrics
Text-rendering benchmarks
CVTG-2k
| Model | open-source | NED | CLIPScore | Word Accuracy 2 regions | Word Accuracy 3 regions | Word Accuracy 4 regions | Word Accuracy 5 regions | Word Accuracy average |
|---|---|---|---|---|---|---|---|---|
| GLM-Image | ✅ | 0.9557 | 0.7877 | 0.9103 | 0.9209 | 0.9169 | 0.8975 | 0.9116 |
| Seedream 4.5 | ❌ | 0.9483 | 0.8069 | 0.8778 | 0.8952 | 0.9083 | 0.9008 | 0.899 |
| Z-Image | ✅ | 0.9367 | 0.7969 | 0.9006 | 0.8722 | 0.8652 | 0.8512 | 0.8671 |
| Qwen-Image-2512 | ✅ | 0.929 | 0.7819 | 0.863 | 0.8571 | 0.861 | 0.8618 | 0.8604 |
| Z-Image-Turbo | ✅ | 0.9281 | 0.8048 | 0.8872 | 0.8662 | 0.8628 | 0.8347 | 0.8585 |
| GPT Image 1 [High] | ❌ | 0.9478 | 0.7982 | 0.8779 | 0.8659 | 0.8731 | 0.8218 | 0.8569 |
| Seedream 4.0 | ❌ | 0.9224 | 0.7975 | 0.8585 | 0.8484 | 0.8538 | 0.8269 | 0.8451 |
| Qwen-Image | ✅ | 0.9116 | 0.8017 | 0.837 | 0.8364 | 0.8313 | 0.8158 | 0.8288 |
| Nano Banana 2.0 | ❌ | 0.8754 | 0.7372 | 0.7368 | 0.7748 | 0.7863 | 0.7926 | 0.7788 |
| TextCrafter | ✅ | 0.8679 | 0.7868 | 0.7628 | 0.7628 | 0.7406 | 0.6977 | 0.737 |
| SD3.5 Large | ✅ | 0.847 | 0.7797 | 0.7293 | 0.6825 | 0.6574 | 0.594 | 0.6548 |
| Seedream 3.0 | ❌ | 0.8537 | 0.7821 | 0.6282 | 0.5962 | 0.6043 | 0.561 | 0.5924 |
| FLUX.1 [dev] | ✅ | 0.6879 | 0.7401 | 0.6089 | 0.5531 | 0.4661 | 0.4316 | 0.4965 |
| 3DIS | ✅ | 0.6505 | 0.7767 | 0.4495 | 0.3959 | 0.388 | 0.3303 | 0.3813 |
| RAG-Diffusion | ✅ | 0.4498 | 0.7797 | 0.4388 | 0.3316 | 0.2116 | 0.191 | 0.2648 |
| TextDiffuser-2 | ✅ | 0.4353 | 0.6765 | 0.5322 | 0.3255 | 0.1787 | 0.0809 | 0.2326 |
| AnyText | ✅ | 0.4675 | 0.7432 | 0.0513 | 0.1739 | 0.1948 | 0.2249 | 0.1804 |
LongText-Bench
| Model | LongText-Bench-EN | LongText-Bench-ZH | |
|---|---|---|---|
| Seedream 4.5 | ❌ | 0.989 | 0.9873 |
| GLM-Image | ✅ | 0.9524 | 0.9788 |
| Nano Banana 2.0 | ❌ | 0.9808 | 0.9491 |
| Qwen-Image-2512 | ✅ | 0.9561 | 0.9647 |
| Qwen-Image | ✅ | 0.943 | 0.946 |
| Z-Image | ✅ | 0.935 | 0.936 |
| Seedream 4.0 | ❌ | 0.9214 | 0.9261 |
| Z-Image-Turbo | ✅ | 0.917 | 0.926 |
| Seedream 3.0 | ❌ | 0.896 | 0.878 |
| X-Omni | ✅ | 0.9 | 0.814 |
| GPT Image 1 [High] | ❌ | 0.956 | 0.619 |
| Kolors 2.0 | ❌ | 0.258 | 0.329 |
| BAGEL | ✅ | 0.373 | 0.31 |
| OmniGen2 | ✅ | 0.561 | 0.059 |
| HiDream-I1-Full | ✅ | 0.543 | 0.024 |
| BLIP3-o | ✅ | 0.021 | 0.018 |
| Janus-Pro | ✅ | 0.019 | 0.006 |
| FLUX.1 [Dev] | ✅ | 0.607 | 0.005 |
General benchmarks
OneIG_EN
| Model | Alignment | Text | Reasoning | Style | Diversity | Overall |
|---|---|---|---|---|---|---|
| Nano Banana 2.0 | 0.888 | 0.944 | 0.334 | 0.481 | 0.245 | 0.578 |
| Seedream 4.5 | 0.891 | 0.998 | 0.35 | 0.434 | 0.207 | 0.576 |
| Seedream 4.0 | 0.892 | 0.983 | 0.347 | 0.453 | 0.191 | 0.573 |
| Z-Image | 0.881 | 0.987 | 0.28 | 0.387 | 0.194 | 0.546 |
| Qwen-Image | 0.882 | 0.891 | 0.306 | 0.418 | 0.197 | 0.539 |
| GPT Image 1 [High] | 0.851 | 0.857 | 0.345 | 0.462 | 0.151 | 0.533 |
| Qwen-Image-2512 | 0.876 | 0.99 | 0.292 | 0.338 | 0.151 | 0.53 |
| Seedream 3.0 | 0.818 | 0.865 | 0.275 | 0.413 | 0.277 | 0.53 |
| GLM-Image | 0.805 | 0.969 | 0.298 | 0.353 | 0.213 | 0.528 |
| Z-Image-Turbo | 0.84 | 0.994 | 0.298 | 0.368 | 0.139 | 0.528 |
| Imagen 4 | 0.857 | 0.805 | 0.338 | 0.377 | 0.199 | 0.515 |
| Recraft V3 | 0.81 | 0.795 | 0.323 | 0.378 | 0.205 | 0.502 |
| HiDream-I1-Full | 0.829 | 0.707 | 0.317 | 0.347 | 0.186 | 0.477 |
| OmniGen2 | 0.804 | 0.68 | 0.271 | 0.377 | 0.242 | 0.475 |
| SD3.5 Large | 0.809 | 0.629 | 0.294 | 0.353 | 0.225 | 0.462 |
| CogView4 | 0.786 | 0.641 | 0.246 | 0.353 | 0.205 | 0.446 |
| FLUX.1 [Dev] | 0.78 | 0.532 | 0.253 | 0.368 | 0.238 | 0.434 |
| Kolors 2.0 | 0.82 | 0.427 | 0.262 | 0.36 | 0.3 | 0.434 |
| Imagen 3 | 0.843 | 0.343 | 0.313 | 0.359 | 0.188 | 0.409 |
| BAGEL | 0.769 | 0.244 | 0.173 | 0.367 | 0.251 | 0.361 |
| Lumina-Image 2.0 | 0.806 | 0.27 | 0.27 | 0.354 | 0.216 | 0.353 |
| SANA-1.5-4.8B | 0.675 | 0.069 | 0.217 | 0.401 | 0.216 | 0.334 |
| SANA-1.5-1.6B | 0.733 | 0.054 | 0.209 | 0.387 | 0.222 | 0.327 |
| BAGEL+CoT | 0.745 | 0.174 | 0.206 | 0.39 | 0.209 | 0.324 |
| SD 1.5 | 0.69 | 0.207 | 0.207 | 0.383 | 0.429 | 0.319 |
| SDXL | 0.688 | 0.029 | 0.237 | 0.332 | 0.296 | 0.316 |
| Show-o2-7B | 0.817 | 0.002 | 0.226 | 0.317 | 0.177 | 0.308 |
| BLIP3-o | 0.711 | 0.133 | 0.223 | 0.361 | 0.229 | 0.307 |
| Show-o2-1.5B | 0.798 | 0.002 | 0.219 | 0.317 | 0.186 | 0.304 |
| Janus-Pro | 0.553 | 0.001 | 0.139 | 0.276 | 0.365 | 0.267 |
OneIG_ZH
| Model | Alignment | Text | Reasoning | Style | Diversity | Overall |
|---|---|---|---|---|---|---|
| Nano Banana 2.0 | 0.843 | 0.983 | 0.311 | 0.461 | 0.236 | 0.567 |
| Seedream 4.0 | 0.836 | 0.986 | 0.304 | 0.443 | 0.2 | 0.554 |
| Seedream 4.5 | 0.832 | 0.986 | 0.3 | 0.426 | 0.213 | 0.551 |
| Qwen-Image | 0.825 | 0.963 | 0.267 | 0.405 | 0.279 | 0.548 |
| Z-Image | 0.793 | 0.988 | 0.266 | 0.386 | 0.243 | 0.535 |
| Seedream 3.0 | 0.793 | 0.928 | 0.281 | 0.397 | 0.243 | 0.528 |
| Qwen-Image-2512 | 0.823 | 0.983 | 0.272 | 0.342 | 0.157 | 0.515 |
| GLM-Image | 0.738 | 0.976 | 0.284 | 0.335 | 0.221 | 0.511 |
| Z-Image-Turbo | 0.782 | 0.982 | 0.276 | 0.361 | 0.134 | 0.507 |
| GPT Image 1 [High] | 0.812 | 0.65 | 0.3 | 0.449 | 0.159 | 0.474 |
| Kolors 2.0 | 0.738 | 0.502 | 0.226 | 0.331 | 0.333 | 0.426 |
| BAGEL | 0.672 | 0.365 | 0.186 | 0.357 | 0.268 | 0.37 |
| Cogview4 | 0.7 | 0.193 | 0.236 | 0.348 | 0.214 | 0.338 |
| HiDream-I1-Full | 0.62 | 0.205 | 0.256 | 0.304 | 0.3 | 0.337 |
| Lumina-Image 2.0 | 0.731 | 0.136 | 0.221 | 0.343 | 0.24 | 0.334 |
| BAGEL+CoT | 0.719 | 0.127 | 0.219 | 0.385 | 0.197 | 0.329 |
| BLIP3-o | 0.608 | 0.092 | 0.213 | 0.369 | 0.233 | 0.303 |
| Janus-Pro | 0.324 | 0.148 | 0.104 | 0.264 | 0.358 | 0.24 |
DPG Bench
| Model | Global | Entity | Attribute | Relation | Other | Overall |
|---|---|---|---|---|---|---|
| Seedream 4.5 | 89.24 | 94.3 | 92.14 | 92.23 | 93.83 | 88.63 |
| Seedream 4.0 | 93.86 | 92.24 | 90.74 | 93.87 | 94.16 | 88.54 |
| Qwen-Image | 91.32 | 91.56 | 92.02 | 94.31 | 92.73 | 88.32 |
| Seedream 3.0 | 94.31 | 92.65 | 91.36 | 92.78 | 88.24 | 88.27 |
| Z-Image | 93.39 | 91.22 | 93.16 | 92.22 | 91.52 | 88.14 |
| Qwen-Image-2512 | 89.04 | 91.91 | 92.39 | 90.85 | 93.07 | 87.2 |
| Lumina-Image 2.0 | - | 91.97 | 90.2 | 94.85 | - | 87.2 |
| Nano Banana 2.0 | 91 | 92.85 | 91.56 | 92.39 | 89.93 | 87.16 |
| HiDream-I1-Full | 76.44 | 90.22 | 89.48 | 93.74 | 91.83 | 85.89 |
| GPT Image 1 [High] | 88.89 | 88.94 | 89.84 | 92.63 | 90.96 | 85.15 |
| Z-Image-Turbo | 91.29 | 89.59 | 90.14 | 92.16 | 88.68 | 84.86 |
| GLM-Image | 87.74 | 90.25 | 89.08 | 92.15 | 90.17 | 84.78 |
| Janus-Pro-7B | 86.9 | 88.9 | 89.4 | 89.32 | 89.48 | 84.19 |
| SD3 Medium | 87.9 | 91.01 | 88.83 | 80.7 | 88.68 | 84.08 |
| FLUX.1 [Dev] | 74.35 | 90 | 88.96 | 90.87 | 88.33 | 83.52 |
| DALL-E 3 | 90.97 | 89.61 | 88.39 | 90.58 | 89.83 | 83.5 |
| Janus-Pro-1B | 87.58 | 88.63 | 88.17 | 89.98 | 88.3 | 82.65 |
| Emu3-Gen | 85.21 | 86.68 | 86.84 | 90.22 | 83.15 | 80.6 |
| PixArt-Σ | 86.89 | 82.89 | 88.94 | 86.59 | 87.68 | 80.54 |
| Janus | 82.33 | 87.38 | 87.7 | 85.46 | 86.41 | 79.66 |
| Hunyuan-DiT | 84.59 | 80.59 | 88.01 | 74.36 | 86.41 | 78.47 |
| Playground v2.5 | 83.06 | 82.59 | 81.2 | 84.08 | 83.5 | 75.47 |
| SDXL | 83.27 | 82.43 | 80.91 | 86.76 | 80.41 | 74.65 |
| Lumina-Next | 82.82 | 88.65 | 86.44 | 80.53 | 81.82 | 74.63 |
| PixArt-α | 74.97 | 79.32 | 78.6 | 82.57 | 76.96 | 71.11 |
| SD1.5 | 74.63 | 74.23 | 75.39 | 73.49 | 67.81 | 63.18 |
TIFF Bench
| Model | Overall short | Overall long |
|---|---|---|
| Nano Banana 2.0 | 91 | 88.26 |
| Seedream 4.5 | 90.49 | 88.52 |
| Seedream 4.0 | 90.45 | 88.08 |
| GPT Image 1 [High] | 89.15 | 88.29 |
| Qwen-Image | 86.14 | 86.83 |
| Seedream 3.0 | 86.02 | 84.31 |
| Z-Image | 80.2 | 83.01 |
| Qwen-Image-2512 | 83.24 | 84.93 |
| GLM-Image | 81.01 | 81.02 |
| Z-Image-Turbo | 77.73 | 80.05 |
| DALL-E 3 | 74.96 | 70.81 |
| FLUX.1 [dev] | 71.09 | 71.78 |
| FLUX.1 [Pro] | 67.32 | 69.89 |
| Midjourney V7 | 68.74 | 65.69 |
| SD 3 | 67.46 | 66.09 |
| SANA 1.5 | 67.15 | 65.73 |
| Janus-Pro-7B | 66.5 | 65.01 |
| Infinity | 62.07 | 62.06 |
| PixArt-Σ | 62 | 58.12 |
| Show-o | 59.72 | 58.86 |
| LightGen | 53.22 | 49.41 |
| Hunyuan-DiT | 51.38 | 53.28 |
| Lumina-Next | 50.93 | 52.46 |
Reference
[1] https://huggingface.co/zai-org/GLM-4-9B-0414
[2] https://huggingface.co/zai-org/CogView4-6B
[3] Liu, Xingchao, Chengyue Gong, and Qiang Liu. "Flow straight and fast: Learning to generate and transfer data with rectified flow." arXiv preprint arXiv:2209.03003 (2022).
[4] Yu, Sihyun, et al. "Representation alignment for generation: Training diffusion transformers is easier than you think." arXiv preprint arXiv:2410.06940 (2024).
[5] Yao, Jingfeng, Bin Yang, and Xinggang Wang. "Reconstruction vs. generation: Taming optimization dilemma in latent diffusion models." Proceedings of the Computer Vision and Pattern Recognition Conference. 2025.
[6] Van Den Oord, Aaron, and Oriol Vinyals. "Neural discrete representation learning." Advances in neural information processing systems 30 (2017).
[7] Geng, Zigang, et al. "X-omni: Reinforcement learning makes discrete autoregressive image generative models great again." arXiv preprint arXiv:2507.22058 (2025).
[8] Ramesh, Aditya, et al. "Hierarchical text-conditional image generation with clip latents." arXiv preprint arXiv:2204.06125 1.2 (2022): 3.
[9] Liu, Shizhan, et al. "Delving into Latent Spectral Biasing of Video VAEs for Superior Diffusability." arXiv preprint arXiv:2512.05394 (2025).
[10] https://huggingface.co/black-forest-labs/FLUX.1-Redux-dev
[11] Zheng, Wendi, et al. "Cogview3: Finer and faster text-to-image generation via relay diffusion." European Conference on Computer Vision. Cham: Springer Nature Switzerland, 2024.
[12] Liu, Zeyu, et al. "Glyph-byt5: A customized text encoder for accurate visual text rendering." European Conference on Computer Vision. Cham: Springer Nature Switzerland, 2024.
[13]Wu, Chenfei, et al. "Qwen-image technical report." arXiv preprint arXiv:2508.02324 (2025).
[14]Zhang, Lvmin, Anyi Rao, and Maneesh Agrawala. "Adding conditional control to text-to-image diffusion models." Proceedings of the IEEE/CVF international conference on computer vision. 2023.
[15] Shao, Zhihong, et al. "Deepseekmath: Pushing the limits of mathematical reasoning in open language models." arXiv preprint arXiv:2402.03300 (2024).
[16] Liu, Jie, et al. "Flow-grpo: Training flow matching models via online rl." arXiv preprint arXiv:2505.05470 (2025).
[17] Ma, Yuhang, et al. "Hpsv3: Towards wide-spectrum human preference score." Proceedings of the IEEE/CVF International Conference on Computer Vision. 2025.
[18] Zhang, Richard, et al. "The unreasonable effectiveness of deep features as a perceptual metric." Proceedings of the IEEE conference on computer vision and pattern recognition. 2018.